Incident du 29/10/2018
Date du post mortem : 02/11/2018
Participants du post mortem :
- Anthony Barré
- Mikael Robert
- Grégoire Lejeune
- Nicolas Alabrune
- Jérôme Lachaud
- Stéphane Rios
- David Rousselie
Description de l'incident
L’incident est à mettre en relation avec l’incident du 23/10/2018. Les mêmes symptômes ont été observés. Le moteur d’optimisation a été ralenti par un phénomène de saturation alors que le nombre de requêtes entrantes sur la plateforme est resté stable. La saturation s’est manifestée à plusieurs niveaux : d’une part au niveau réseau sur la bande passante consommée entre les noeuds du moteur (proxy/worker) et d’autre part au niveau du processus gérant la répartition des tâches au sein du moteur (broker).
Le ralentissement est de l’ordre de 500ms sur le temps de réponse pour une partie des pages, certaines pages sont ralenties plus fortement à cause de la saturation de la bande passante.
La cause de l’incident réside dans le traitement en temps réel de fichiers HTML de plusieurs Mo.
Timeline
12h17 : des pages HTML de plusieurs Mo arrivent en traitement sur la plateforme
12h19 : première alerte reçue sur l’astreinte via notre système de monitoring concernant un nombre d’optimisation élevé en erreur
12h25 : alertes sur l’overhead
12h35 : équipe tech réunie sur le sujet
On constate au même moment, un pic de retransmission TCP et une saturation de la bande passante :

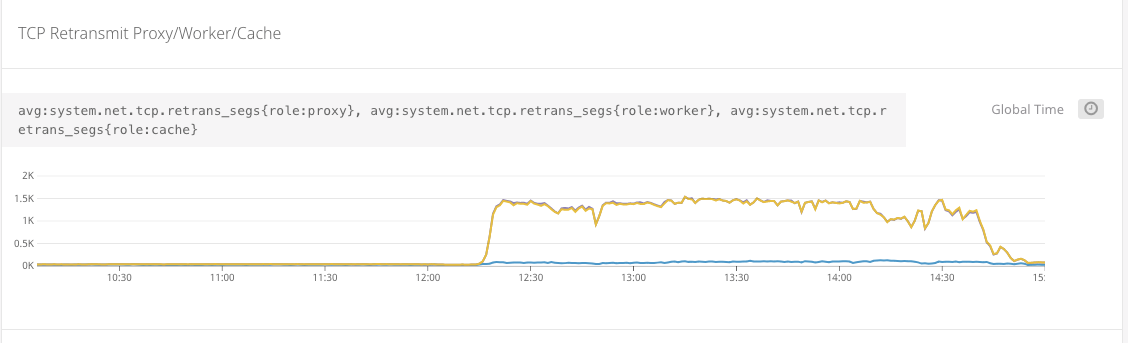

Entre 12h15 et 14h00 : plusieurs pistes sont étudiées pour résoudre le problème : le redémarrage des processus ne permet pas d’améliorer la situation.
14h09 : un nouveau proxy est ajouté. Cela ne permet pas de soulager le système. Le proxy est affecté par les mêmes problèmes et présente les mêmes symptômes.
14h30 : nous ne recevons plus de pages HTML de plus de 5 Mo
14h40 : modification des réglages des brokers pour augmenter le temps alloué à la réception d’un ACK provenant des workers ainsi qu’une diminution du nombre de réessais possibles pour chaque tâche.
Entre 14h40 et 15h15 : le phénomène perd progressivement de son intensité jusqu’à disparaître.
Analyse des causes de l’incident
A partir de 12h15, le moteur d’optimisation a reçu d’énormes fichiers HTML (5-10Mo décompressés, hors ressources) à un rythme soutenu. Ces fichiers ont occupé les workers pendant 100 fois plus de temps qu’en régime normal et ont globalement saturé la capacité de notre moteur d’optimisation.
Ces fichiers HTML sont décompressés par nos workers. Après être optimisés, ces fichiers sont retransmis aux proxys de façon décompressés. Les workers ont alors saturé la bande passante des proxys.
Le fait que l’ensemble des workers et des proxys soit partagé pour l’ensemble de nos clients a progressivement impacté l’ensemble du trafic.
En plus de saturer la bande passante, la mémoire des brokers a augmenté fortement. Cela vient du fait que les fichiers sont bufferisés au niveau du broker.
La dégradation réseau a engendré des difficultés de communication entre workers et brokers, ainsi que des problèmes de visibilité des workers disponibles. Cela a fortement complexifié la distribution des tâches : les brokers ont toujours distribué des tâches aux workers mais un certain nombre de tâches n’ont pas pu être distribuées dans les temps impartis. Un système de redistribution des tâches est alors enclenché, ce qui a aggravé le phénomène de saturation réseau.
L’incident s’est terminé quand les fichiers incriminés (> 5 Mo) ont cessé d’être transmis par les origines.
Faits et Timeline
* à quel moment la première personne pouvant corriger le problème a été avertie ? 12h19
* à quel moment le problème a été corrigé ? 14h40
Métriques
Niveau de sévérité de l'incident
sévérité 2 / dégradation du site, problème de performance et/ou feature cassée avec difficulté de contourner impactant un nombre significatif d'utilisateur
Rappel :
* Sévérité 1: arrêt du site non planifié qui affecte un nombre significatif d'utilisateurs
* Sévérité 2 : dégradation du site, problème de performance et/ou feature cassée avec difficulté de contourner impactant un nombre significatif d'utilisateurs
* Sévérité 3: problème mineur qui a un impact sur les utilisateurs minimal et des contournements faciles
Time to detect
2 minutes
Time to resolve
2h23
Impacts
Sur le client (usages, images)
* Combien de client impactés nombre absolu ? tous
* Quelle proportion des clients impactés ? 100%
* Quelle proportion des clients utilisant la feature problématiques impactés ? 100%
Sur l'entreprise (CA...)
Difficile à estimer. Perte de quelques clients. Perte de confiance.
Contre mesures
court terme
- amélioration du monitoring des brokers sur les temps de transferts des messages
- réduction du nombre d’essais de soumission d’une tâche à un worker pour réduire l’effet d’amplification
- exclusion des fichiers trop larges et non cachables de l’optimisation synchrone (pour gzip, deflate, brotli)
- ajouter davantage d’informations sur la taille et le type des ressources dans les logs de notre moteur
- ajout d’alertes sur les dépassements de seuil de bande passante.
moyen terme
- possibilité de passer en mode debug de façon simplifiée
- transférer des fichiers compressés aux proxys
- avoir une vue sur les percentiles 95 des métriques de temps d’optimisations (response_time, optimization_time, etc …)
- étudier la possibilité de prendre en compte les workers dans les sondes de disponibilité des proxys
long terme
- service mesh et tracing distribué des échanges réseaux inter-services.
- isolation des grands comptes / implémentation shuffle sharding
Plan d'actions
Quoi/qui/quand
- création des issues / équipe tech / lundi 05/11/2018
Prochain point d’avancement du plan d’action : lundi 05/11/2018